
Large language models (LLMs) often appear to be in a fight to claim the title of largest and most powerful, but many organizations eyeing there use are beginning to realize big isn’t always better.
The adoption of generative artificial intelligence (AI) tools is on a steep incline. Organizations plan to invest 10% to 15% more on AI initiatives over the next year and a half compared to calendar year 2022, according to an IDC survey of more than 2,000 IT and line-of-business decision makers.
And genAI is already having a significant impact on businesses and organizations across industries. Early adopters claim a 35% increase in innovation and a 33% rise in sustainability because of AI investments over the past three years, IDC found.
Customer and employee retention has also improved by 32%. “AI will be just as crucial as the cloud in providing customers with a genuine competitive advantage over the next five to 10 years,” said Ritu Jyoti, a group vice president for AI & Automation Research at IDC. “Organizations that can be visionary will have a huge competitive edge.”
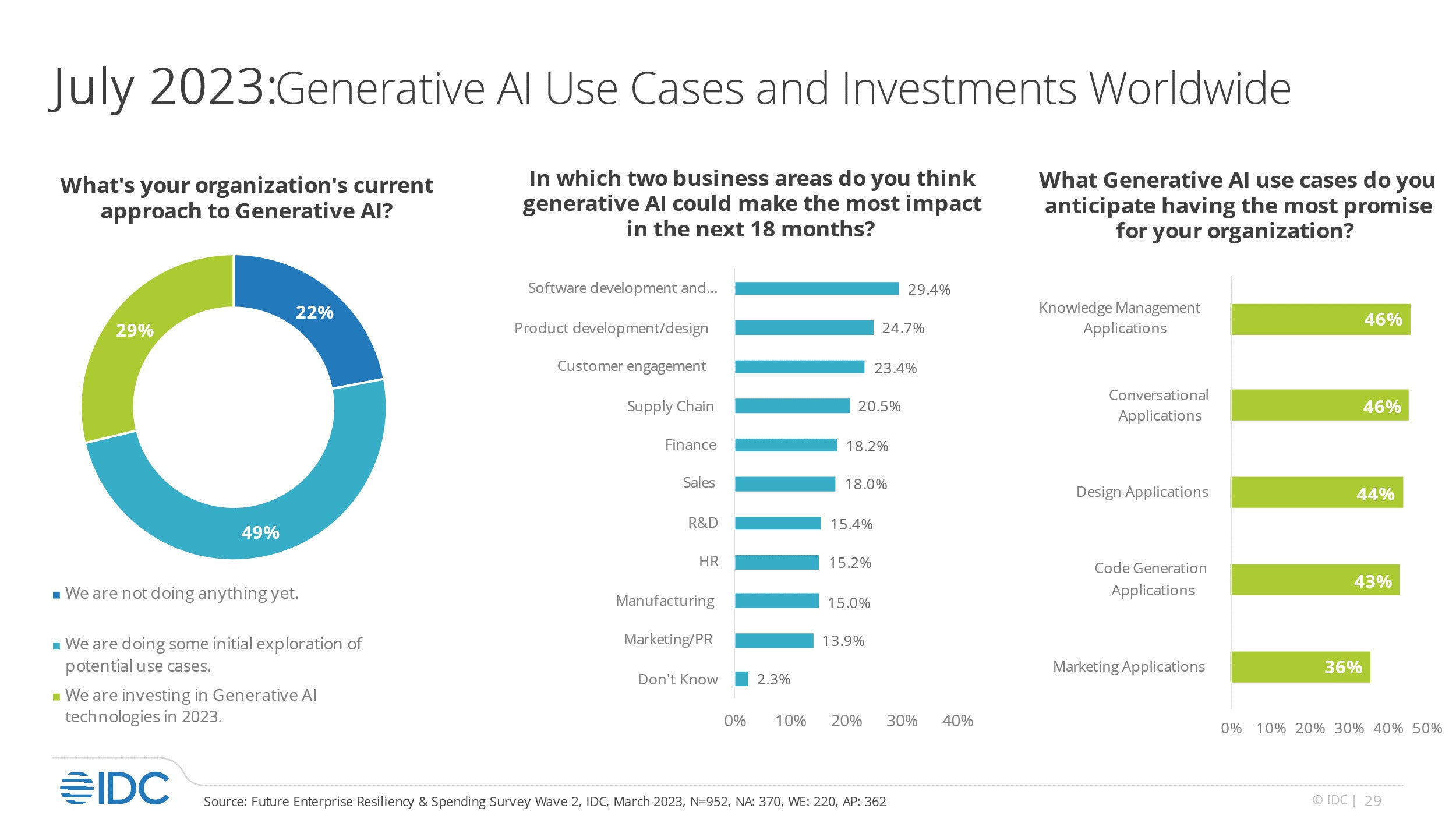 IDC
IDCWhile LLMs with hundreds of billions or even a trillion parameters might sound powerful, they’re also devouring compute cycles faster than the chips they require can be manufactured or upscaled; that can strain server capacity and lead to an unrealistically long time to train models for a particular business use.
“Sooner or later, scaling of GPU chips will fail to keep up with increases in model size,” said Avivah Litan, a vice president distinguished analyst with Gartner Research. “So, continuing to make models bigger and bigger is not a viable option.”
Dan Diasio, Ernst & Young’s Global Artificial Intelligence Consulting Leader, agreed, adding that there’s currently a backlog of GPU orders. A chip shortage not only creates problems for tech firms making LLMs, but also for user companies seeking to tweak models or build their own proprietary LLMs.
“As a result, the costs of fine-tuning and building a specialized corporate LLM are quite high, thus driving the trend towards knowledge enhancement packs and building libraries of prompts that contain specialized knowledge,” Diasio said.
Additionally, smaller models trained on more data will eventually challenge the dominance of today’s leading LLMs, such as OpenAI’s GPT 4, Meta AI’s LLaMA 2 or Google’s PaLM 2.
Smaller models would also be easier to train for specific use cases.
LLMs of all sizes are trained through a process known as prompt engineering — feeding queries and the correct responses into the models so the algorithm can respond more accurately. Today, there are even marketplaces for lists of prompts, such as the 100 best prompts for ChatGPT.
But the more data ingested into LLMs, the the greater the possibility of bad and inaccurate outputs. GenAI tools are basically next-word predictors, meaning flawed information fed into them can yield flawed results. (LLMs have already made some high-profile mistakes and can produce “hallucinations” where the next-word generation engines go off the rails and produce bizarre responses.)
For vertical industries or specialized use, massive general purpose LLMs such as OpenAI’s GPT 4 or Meta AI’s LLaMA can be inaccurate and non-specific use even though they contain billions or trillions of parameters. A parameter is something that helps an LLM decide between different answers it can provide to queries.
Though “mega LLMs” use well-understood technology — and continue to improve — they can only be developed and maintained by tech giants with the enough resources, money and skills to do so, Litan argued.
“That consolidates the power of LLMs with a few dominant players, and that centralization is an enormous risk in itself,” she said. “Centralization of enormous technological power amongst just a handful of players is always a bad idea. There are no meaningful checks and balances on these companies. And the chip industry cannot keep up. GPU innovation is moving slower than the widening and growth of model sizes. Hardware is always slower to change than software.”
Training up LLMs for specific organizational use
While models like GPT 4 are pre-filled and trained with massive amounts of information drawn from the Internet and other sources, prompt engineering allows genAI users to adjust responses by using either proprietary or industry-specific information. For example, a user organization could connect chatGPT to its backend applications and databases with native APIs; the genAI tool can then draw on that proprietary company information for more business-specific uses.
According to a new survey of 115 CFOs by Deloitte, 42% said their companies are experimenting with GenAI, and 15% are building it into their strategy. Roughly two-thirds of surveyed CFOs say less than 1% of next year’s budget will be spent on GenAI, and about one-third of CFOs project 1% to 5% to go toward the emerging technology.
For 63% of CFOs the greatest barriers to adopting and deploying GenAI are talent resources and capabilities. In light of a lack of internal talent, a growing number of tech firms have unveiled genAI tools based on LLMs that can automate business tasks or help users handle redundant or repetitive tasks.
In March, Salesforce announced plans to release a GPT-based chatbot for use with its CRM platform. That same month, Microsoft announced its GPT-4-based Dynamics 365 Copilot, which can automate some CRM and ERP tasks. Other genAI platforms can assist in writing code or performing HR functions, such as ranking job applicants from best to worst or recommending employees for promotions.
The big LLM creators are also beginning to tailor their models for specific industry uses.
For example, Google now offers two domain specific models: Med-PaLM 2, its medically-tuned version of PaLM 2, which will be available next month as a preview to more customers in the healthcare and life sciences industry, and Sec-Palm, a version fine-tuned for security uses. The latter incorporates security intelligence such as Google’s visibility into the threat landscape and Mandiant’s frontline intelligence on vulnerabilities, malware, threat indicators, and behavioral threat actor profiles.
 Shutterstock/Robert Way
Shutterstock/Robert Way Google also offers Vertex AI, a set of tuning methodologies used to customize its PaLM 2 LLM or — it claims — any third-party or open-source model.
“Our customers use these tuning methods to customize for their specific business use cases and leverage their own enterprise data, while providing guidance around which approach is best for their use case, business objectives, and budget,” a Google spokesperson said in an email response to Computerworld.
Vertex AI offers customization features such as prompt tuning and adapter tuning, which requires a bigger training dataset — from hundreds to thousands of examples — and a small amount of computing power to train, the spokesperson said.
It also offers “reinforcement learning with human feedback,” which takes human feedback on the outputs to tune the model using Vertex AI pipelines.
Start-ups are also entering the fray, creating vertical-specific LLMs or fine tuning models for their clients.
Writer, for example, is a start-up that offers a full-stack, genAI platform for enterprises; it can support business operations, products, sales, human resources operations, and marketing. The company offers a range of language models that cater to specific industries. The company’s smallest model has 128 million parameters, the largest — Palmyra-X — has 40 billion.
“We fine-tune our base models to support industry verticals,” said May Habib, co-founder and CEO of Writer.
For example, to create Palmyra-Med — a healthcare oriented model — Writer took its base model, Palmyra-40B, and applied instruction fine-tuning. Through this process, the company trained the LLMs on curated medical datasets from two publicly available sources, PubMedQA and MedQA.
“Smaller models are becoming viable options that are available to many researchers and end-users today, and spreading the AI ‘wealth’ around is a good idea from a control and an solution point of view,” according to Litan. “There are many experiments and innovations that show smaller models trained on much more data (e.g., five to 10 times more) or curated data, can come close to the performance of the mega LLMs.”
In February Facebook-parent Meta released versions of its LLaMa LLM in sizes ranging from seven to 65 billion parameters, vastly smaller than previous models. It also claimed its 13-billion-parameter LLaMA model outperformed the much larger GPT-3 model on most benchmarks. Meta said its smaller LLM would “democratize” access to genAI by requiring less “computing power and resources to test new approaches, validate others’ work, and explore new use cases.”
There are other innovations taking place at Stanford, Nvidia, and across academic institutions such as John Hopkins, which launched the BabyLM challenge to create significantly smaller models that are nearly as good as the largest LLMs. “All of these still have to prove themselves beyond the research labs, but progress is moving forward,” Litan said.
There are also other techniques being tested, including one that involves training smaller sub-models for specific jobs as part of a larger model ecosystem.
“We are seeing the concern from enterprises about using a model like GPT, or PaLM because they’re very large and have to be hosted by the model providers. In a sense your data does go through those providers,” said Arvind Jain, CEO of Glean, a provider of an AI-assisted enterprise search engine.
Glean’s search engine relies heavily on LLMs such as GPT 4, PaLM 2 and LLaMA 2 to match user queries to the enterprise from which they’re seeking data or internal documents.
Among the concerns that remain with cloud-based LLMs are security, privacy and copyright infringement issues. OpenAI and Google now offer assurances they will not misuse client data to better customize their LLMs, said Jain, a former distinguished engineer for Google. And enterprises are accepting those assurances, Jain said.
Along those lines, OpenAI just released its ChatGPT Enterprise application, offering organizations increased security and privacy through encryption and single sign-on technology.
Derek Holt, CEO of Digital.ai, a service that uses AI to produce end-to-end software development and delivery, said smaller, better-tailored LLMs are emerging from startups such as Pryon that allow organizations to build their own LLMs quickly. “The idea being: ‘we’ll build one through the context of our enterprises data,’” Holt said.
Matt Jackson, global CTO at systems integration services provider Insight Enterprises, said there are definite advantages for some usersof a more “focused” LLM. For example, the healthcare and financial services industries are experimenting with smaller models trained on specific data sets.
Amazon is also releasing its own LLM marketplace with smaller models organizations can train using their own enterprise data.
“For most, training their own model is probably not the right approach. Most companies we work with are perfectly suited using ChatGPT, Langchain, or Microsoft’s cognitive search engine. The LLM is a blackbox that’s pretrained. You can allow that to access your own data,” Jackson said.
Building a custom LLM is hard, and expensive
Currently, there are hundreds of open-domain LLMs contained in online developer repositories such as Github. But the models tend to be much smaller than those from established tech vendors, and therefore far less powerful or adaptable.
On top of that, building proprietary LLMs can be an arduous task; Jain said he’s not come across a single client that’s successfully done so, even as they continue to experiment with the technology.
“The reality right now is the models that are in open domain are not very powerful. Our own experimentation has shown that the quality you get from GPT 4 or PaLM 2 far exceeds that of open-domain models,” Jain said. “So, for general purpose applications, it’s not the right strategy right now to build and train your own models.”
Copyright © 2023 IDG Communications, Inc.